Spotify System Design interview
Table of Contents
Spotify System Design Interview
Functional Requirement
- Upload audio song mp3
- Listen to songs
- Create playlist
- Artists
- Podcasts
- Like a song
- Share a song
Reduced scope
- Search a song
- Listen to song
Non Functional Requirement
- High availability
- System should be available all the time
- no downtime
- Scalable
- System should able to handle millions of upload
- System should able to handle billions of song streaming / listening
- Low latency
Metrics
- Number of songs : 100 million
- Single song size : 5 MB
- Total storage for raw song
- 100 Million * 5 MB = 500 TB = 0.5 PB
- 3 X replica = 1.5 PB
- Total storage for song’s metadata : 100 Bytes
- 1 KB * 100 million = 100 GB
- Total Users : 1 billions
- Total storage for User
- 1 Billions * 1KB = 1 GB * 1 KB = 1 TB
- Daily active users
- Daily song listen by active users
- Calculate QPS or transaction per second
- Peak load handling
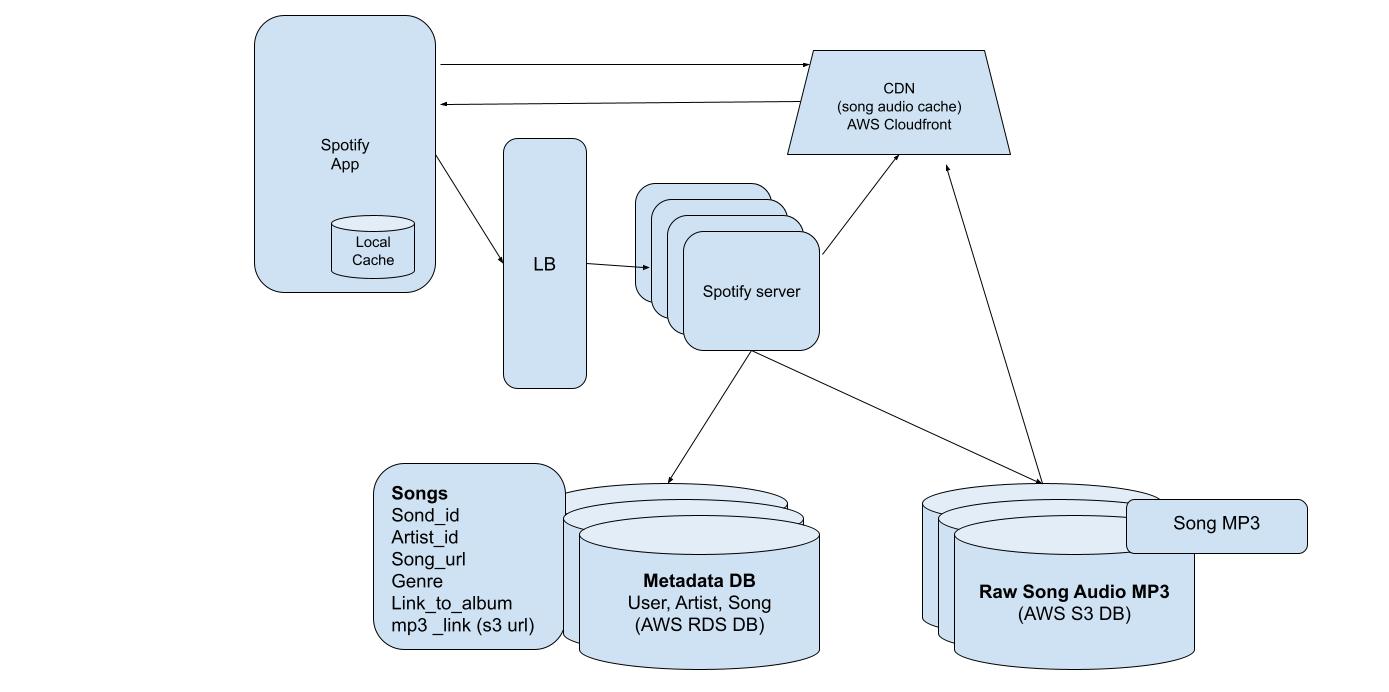
Database Design
We need to maintain below types of data tables i.e User, Artist Song’s metadata and actual song data.
Below 3 parameters decides which db to be used.
- Access pattern
- Size of data
- Types of queries
Here, metadata can be modified, queried frequently, so SQL db makes sense.
Raw data of song is not going to change once uploaded and it will be streamed, so AWS s3 works well here.
A. User, Artist
- We can use relational DB like MYSQL , Aurora
- user_id
- <meatadata> login, passoword etc.
B. Song Metadata
- We can use relational DB like MYSQL , Aurora
- song_id
- song_url
- genre
- duration
- artist_id
C. Raw data of song
- This is immutable raw data and will be used for streaming
- We can use blob storage like S3
Use Cases
Search a song
- User can type or use filters in app to provide input to app server for searching a song.
- This input will be translated to a backend query for metadata db and we can get a list of song in response.
- e.g. searching for Korean pop song genre can return 100 songs from backend servers.
Playing a song
- Once user click on particular song, that will get translated to an API call from app to webserver via LB.
- Webserver will fetch metadata of a song where song is saved i.e. s3 location.
- Since this is 5 MB data, we can keep it in memory of webserver and then start streaming, it should be instantaneous.
Potential bottleneck
- We need to check for keeping s3 data in memory as it can bloat the web server instance memory.
Shared Cache for App Server
- We can keep distributed shared cache between app server and clients.
- This can help reduce the load on app server if some server already served a particular audio request earlier.
Content Delivery Network (CDN)
- First level of reducing possible bottleneck on web server is to introduce CDN in our architecture.
- CDN will help to save most frequently played song on CDN which are close to users.
- It also acts as a cache reducing response time and overall incoming request load.
- Another level of caching we can maintain in app itself, it user is playing that song multiple times in a day.
Replica of DB’s
- We need to choose geo aware strategies for data placement and replication to make overall system more performant effective.
- e.g. Korean pop songs of BTS will be more popular in korea, asia region.
- Keep replica of audio close to location where it is access more frequently i.e. replicas placement algorithm should be geo aware.
Load Balancing
- Load balancer needs to route request based on load on the application servers i.e. number of request it is currently serving.
- Simple round robin strategy can be used here.
- Along with this, we need to take care of load balancing from how many bytes of data a particular server is transferring i.e. based on network I/O load.
- In this case, cpu load may be less compared to network I/O.
Please visit https: https://codeandalgo.com for more such contents.