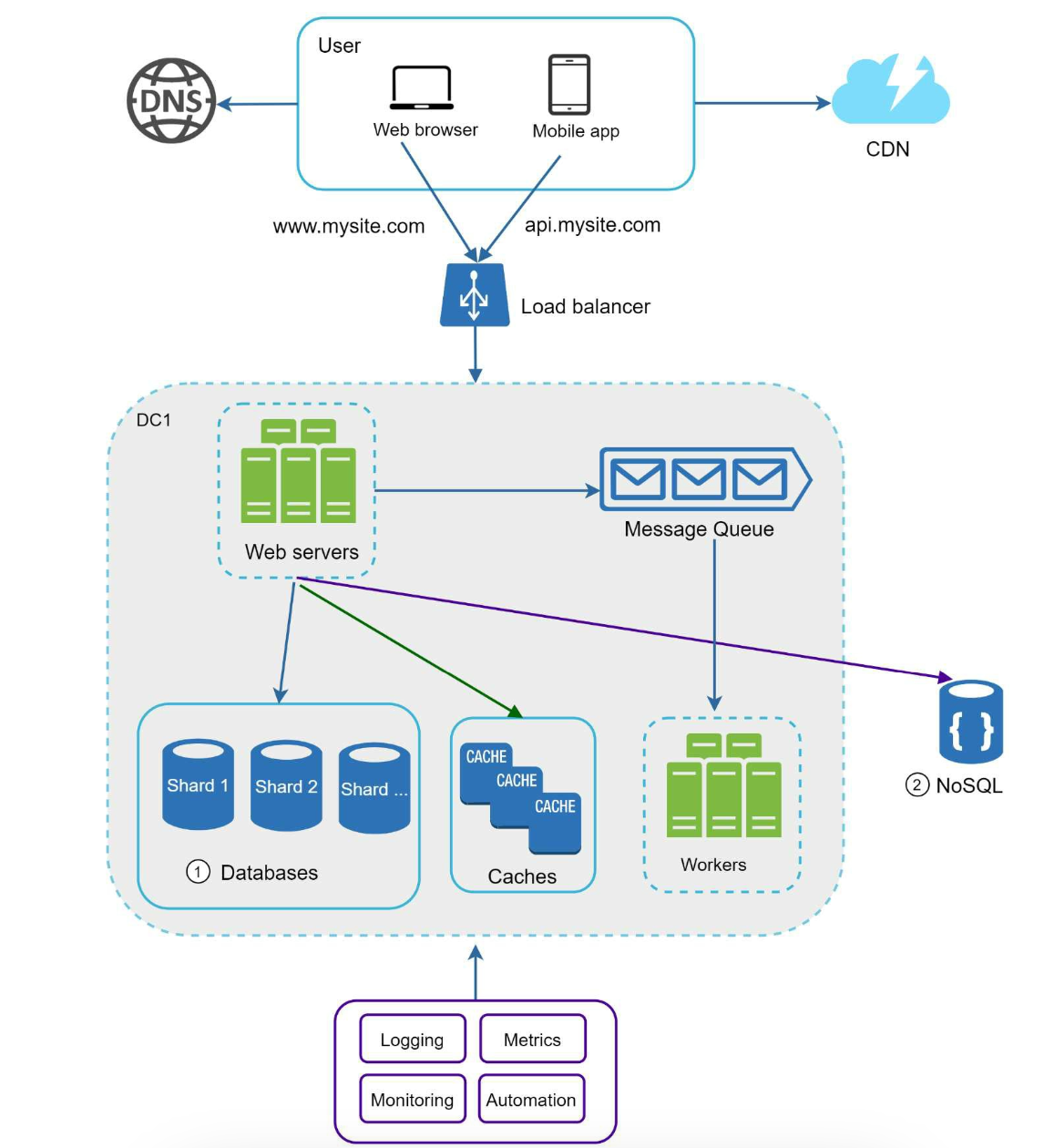
System Design Concepts
Table of Contents
System Design Concepts
Scalability
- One of the biggest challenge faced by engineer in big tech is scalability after coming up with clever algorithm or system.
- They need to build system is such a ways that it should handle thousands of transactions per second (QPS) & petabytes of data.
- In short, we have to design system at scale.
- Luckily, most of the problems are already solved by other big tech companies, we just need to understand them and reuse them.
- Horizontal partitioning solves a lot of scalability problem.
Problem Statement
How to design system that can handle millions of request at once ?
To answer this we will start with simple solution
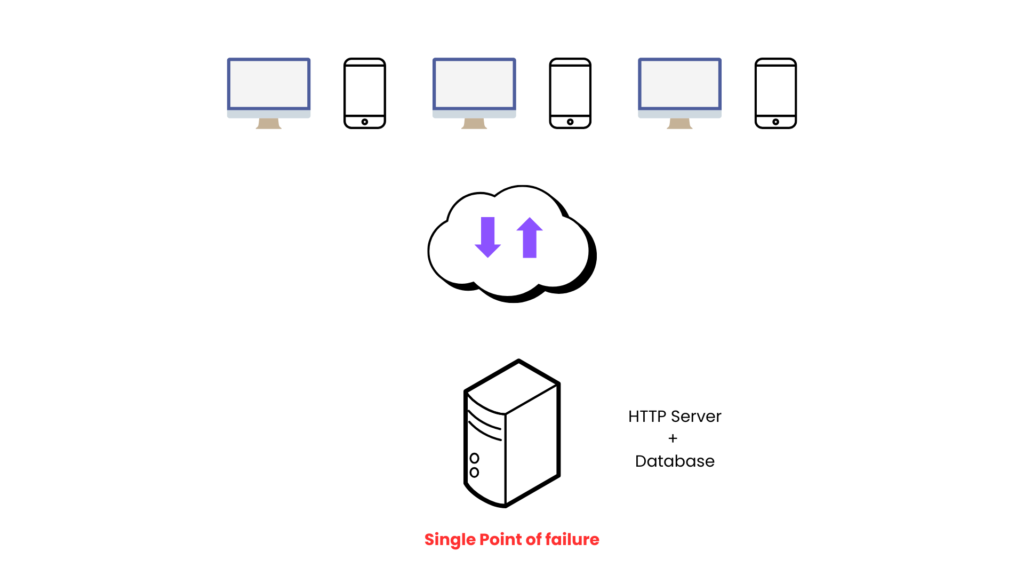
Single server design
- This is good for where we dont care too much about data.
- Its just personal space on web maybe wordpress website.
- And even if it goes down, you can make it available using manual back up copy.
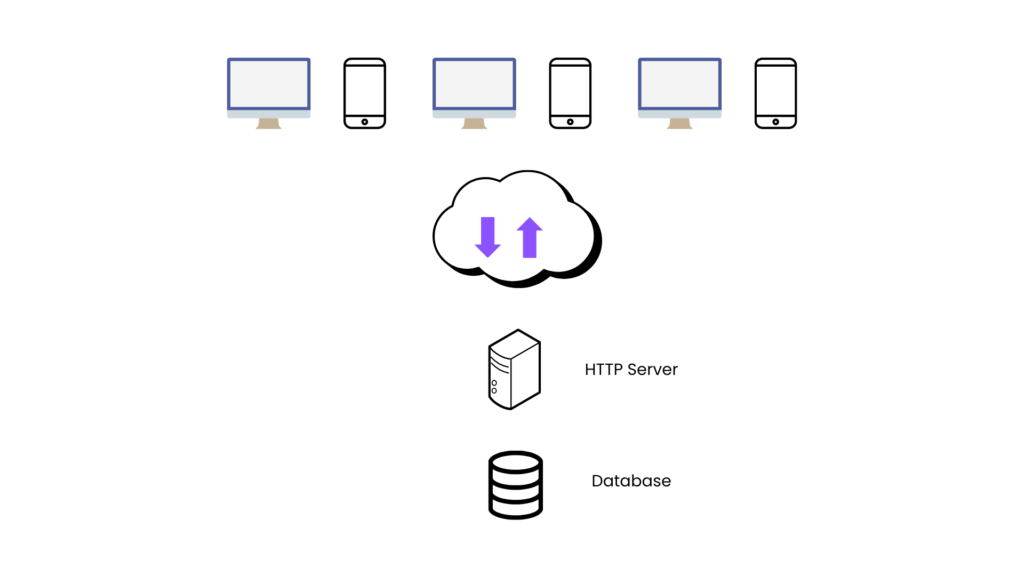
Separating Server and Database
- Separating out DB is better than keeping server and db together on same system.
- If server goes down, at least we will have our data safe.
- But server and db are still having single point of failure problem because of single instance of each of them.
Horizontal vs Vertical Scaling
Vertical Scaling
- One of the solution to handle many request is to increase system resources i.e. vertical scaling.
- But it has its practical limitation with hardware resources & single point of failure is still exist.
- So Vertical scaling does not solve the problem entirely.
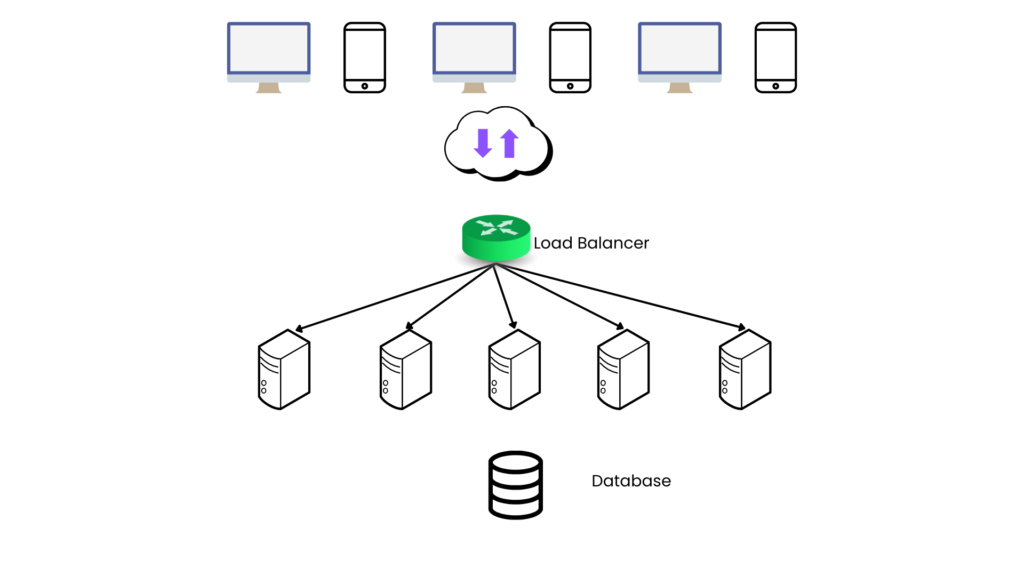
Horizontal Scaling
- Idea is to distribute the request (load) uniformely across servers.
- To distribute the load as server number increases in future, is a completed different problem altogether. We will discuss in separate article.
- Once we add more than one server, we have make changes to out original system/algorithm.
- Now, it can not be stateful.
- It has to be stateless. i.e. any server can not hold client specific context (information) in memory to avoid hard coupling of client and servers.
- In requests coming from client can go to any available server
- i.e. Request-1 from client-1 can go to server-1 &
- Request-2 from client-1 can go to server-2
FailOver Strategies
- These server can physically be located in an organisation, but it has its own problem. Space, maintainance, purchasing new hardware as company scales etc.
- Other way is to leverage cloud services like Amazon web server, Google Cloud Provider, Microsoft Azure etc.
- Here, we can rent out VM’s like AWS EC2, Google Compute enigne, Azure VM.
- But we have to look after its whole lifecycle like turning on/off as required.
- Advantage is that we can ask to bring up these servers in different geographical regions, different datacenters.
- Fault Tolerant : So in case one geo graphical region server goes down , we will still have out web services up and running from other region.
- Another way is to use ServerLess services i.e. AWS Lambda where we pay for the number of transactions for which services are used.
Scaling the Database
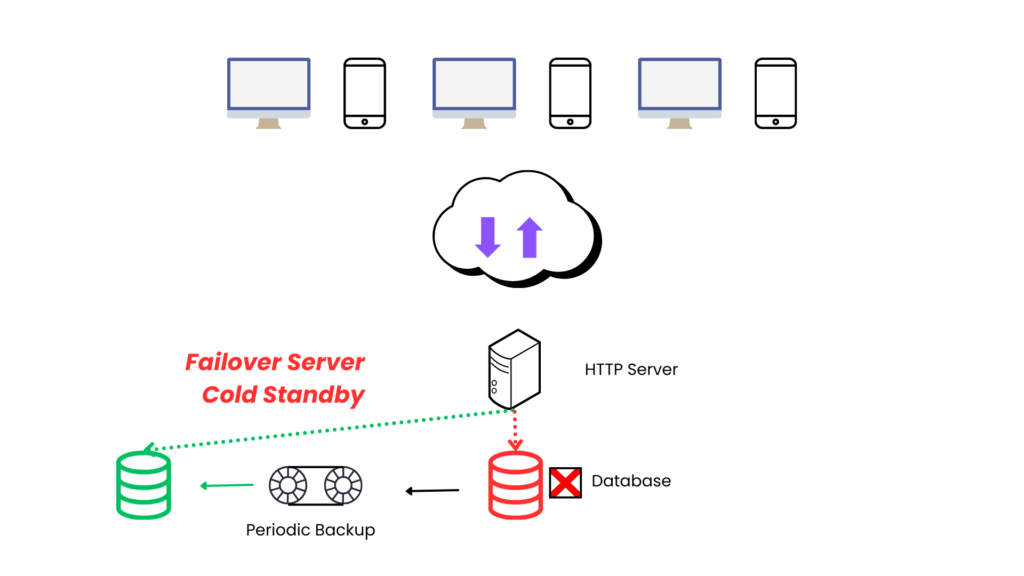
Failover servers : Cold Standby
- If primary DB goes down, we can have a more downtime.
- Because first we need to copy data from periodic backup to standby DB & then reroute the request from servers to new standby server.
- Another problem is that new incoming data after last backup will be lost.
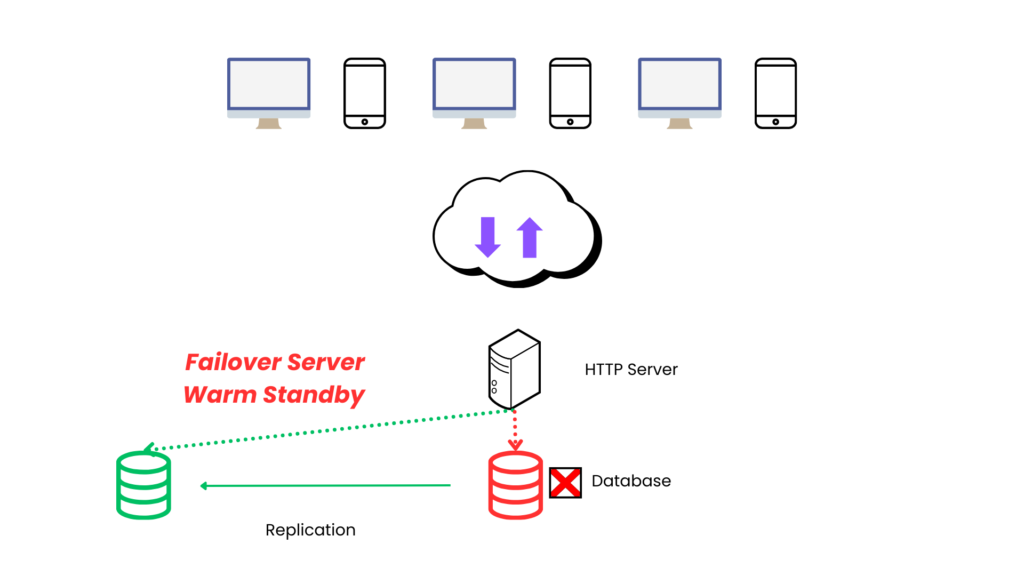
Failover servers : Warm Standby
- We can have another db instance which is keeping up with primary db and ready to go at all the time.
- We can use replication feature provided by db or another server can sync data offline.
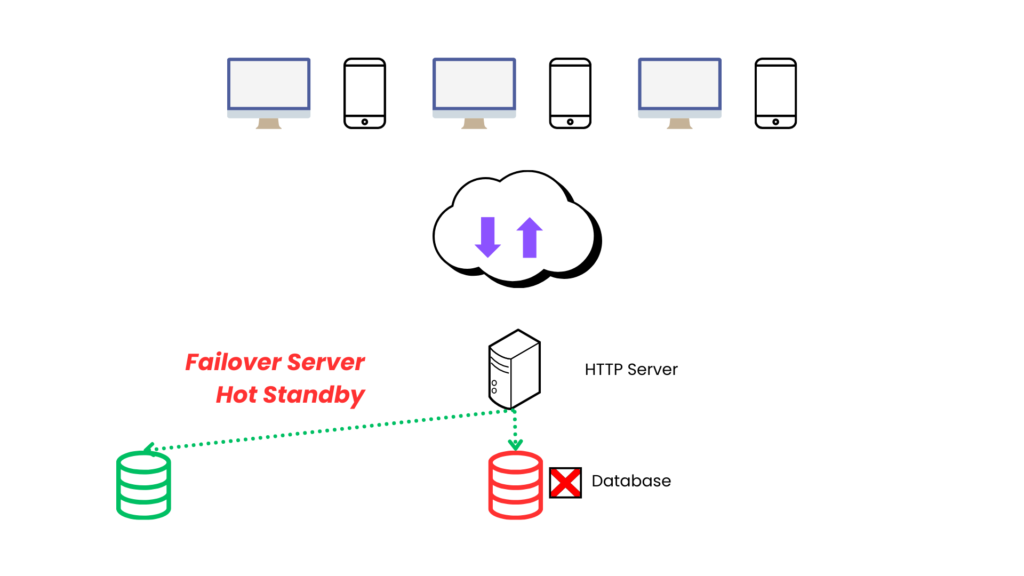
Failover servers : Hot Standby
- Here the front web server will write data to both db instances simultaneouly.
- Advantage : We can distribute the read request as well as latest data will be available on all instances.
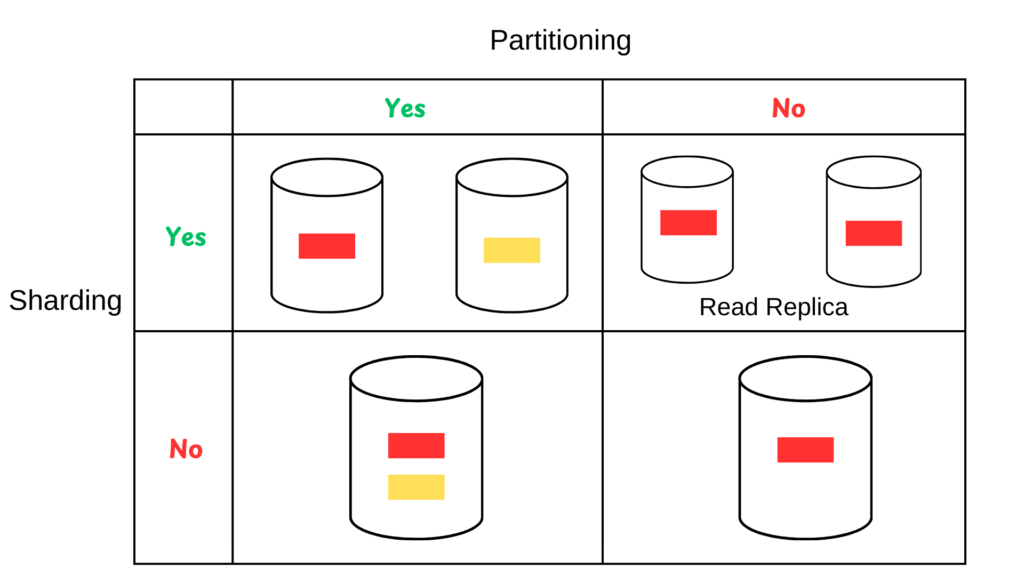
Sharding Databases / No SQL
What is difference between DB Sharding vs Data Partitioning ?
Sharding
- Method of distributing the data across multiple machines.
- Database server is sharded.
- Shards are physical/virtual DB servers.
Partitioning
- Splitting the subset of data within same instance.
- Data is partitioned.
- Partitioning Types
- Horizontal Partitioning
- handle data at document or row level
- Vertical partitioning
- handle data at column level or table level.
- Horizontal Partitioning
How to partition the data ?
- It needs to done using some smart logic that depends on
- Access pattern
- Load
- Use case
Case -1 : Partition : Yes, Shard : Yes
- Data is partitioned and Sharded as well
- To handle large number of writes and provides higher throughput
Case -2 : Partition : No, Shard : Yes
- Data is sharded and but not partitioned
- Writes and strongly consistent read will be handled from primary shards.
- To handle large number of reads from read replica.
Case -3 : Partition : Yes, Shard : No
- Data is partitioned and but not sharded
- Logical data partition is done, but kept on single instance of server.
- e.g. There will 2 database on same my mysql instances.
- Order books
- Listing of books
- Not much of load, but ready to be scaled using sharding in near future.
Case -4 : Partition : No, Shard : No
- Data is not sharded and but not partitioned
- Simple application where we don’t need logical data parition and shards as well.
- Day 0 scenario where we just started our new app.
Sharding details
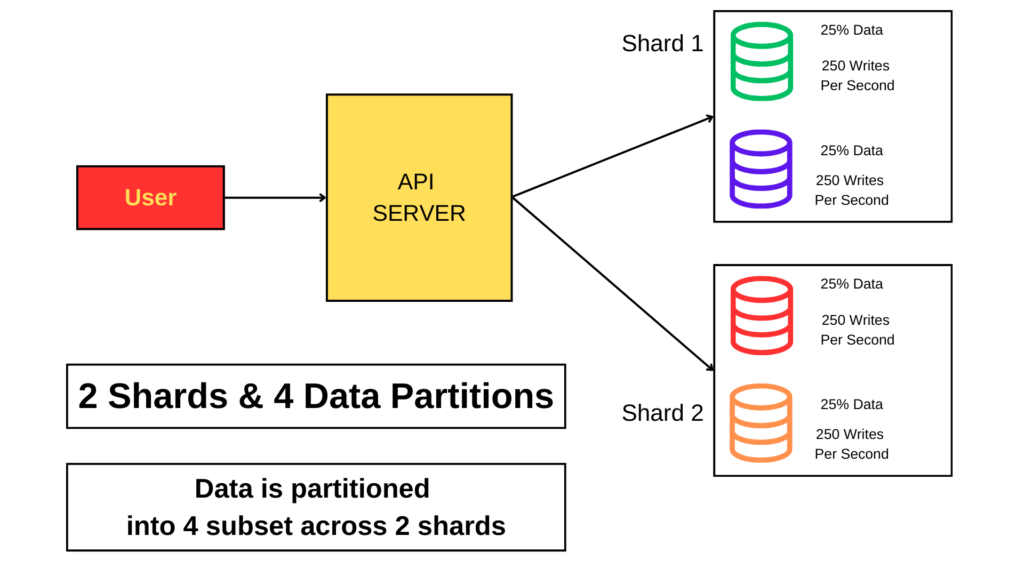
- Sharding is fundamental idea behind lot of modern, scalable database technologies.
- Shard is horizontal partitions of your database.
- Particular subset of data is send to one shard#1 (e.g. User#1) and other subset will be sent to shard#2 (e.g. User#2).
- We can use Hash function to partition the data into shards and each shards will have its own backup mechanism to maintain hot standby ready.
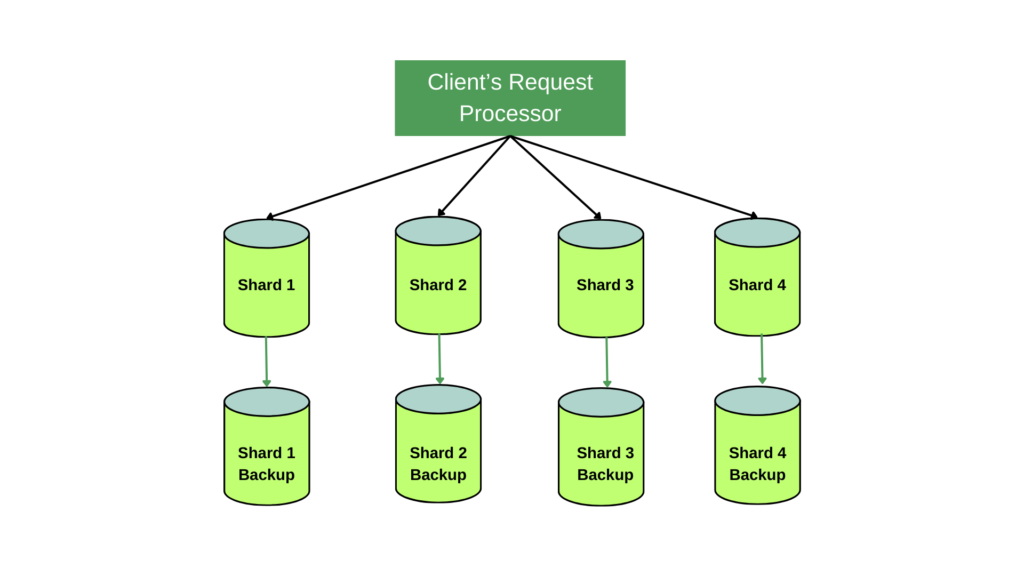
Scalability
- This achieves scalability as data grows, we can keep adding more and more shards.
Resiliency
- If one shard host goes down, there is another backup host ready to take its place.
Design
- We want to design applications that will minimize joins or the complex sql queries across shards.
- Also, how to structure data so that, simple key value pair query will achieves the end goal
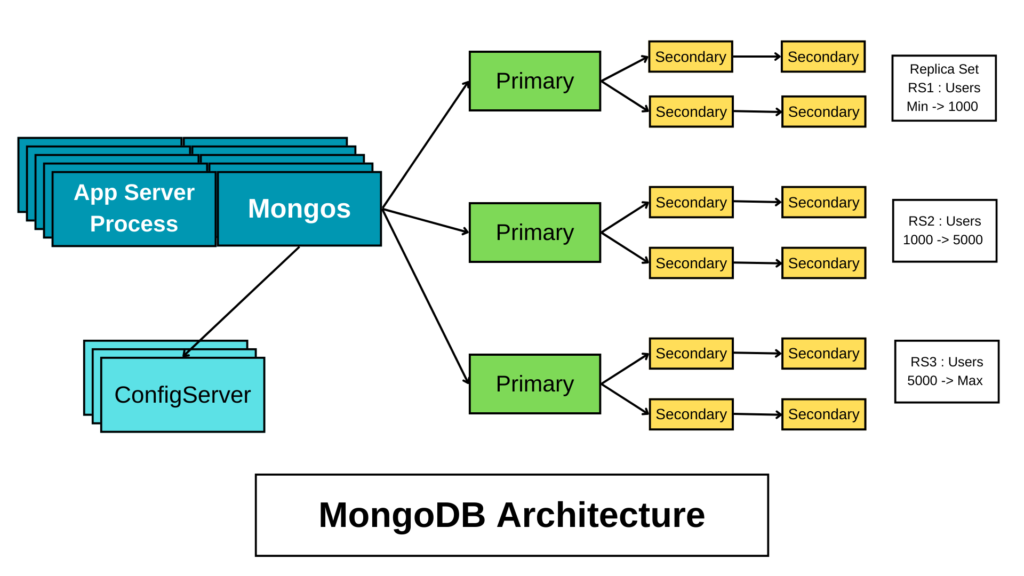
MongoDB Use Case
Replica Set
- A replica set is a group of MongoDB nodes that maintain the same dataset to provide redundancy and high availability.
- It consists of:
- Primary Node: Handles all write and most read operations (if not using read preferences).
- Secondary Nodes: Replicate data from the primary and can handle read queries if configured with read preferences.
Mongos
- Mongos acts as a query router in a sharded cluster.
- It interacts with the config servers to determine the metadata and routing of queries.
- It directs client queries to the appropriate shards based on the sharding key and distributes the load across the cluster.
Config Server
- A config server stores metadata about the cluster, including:
- Information about each shard (typically a replica set).
- Details of how the data is partitioned (sharded) across the shards.
- Config servers ensure consistency in sharded clusters and help Mongos route queries correctly.
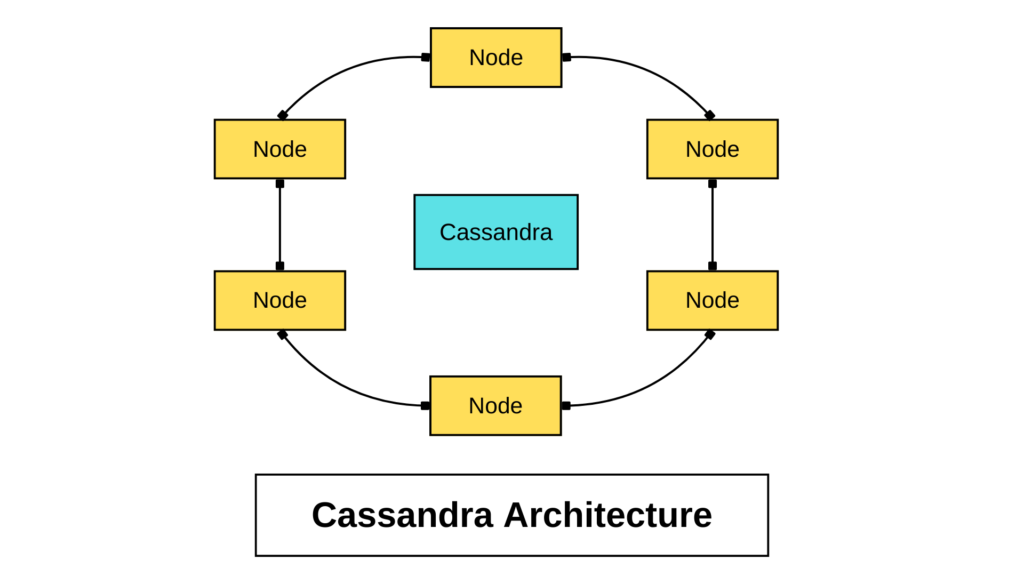
Cassandra Use Case
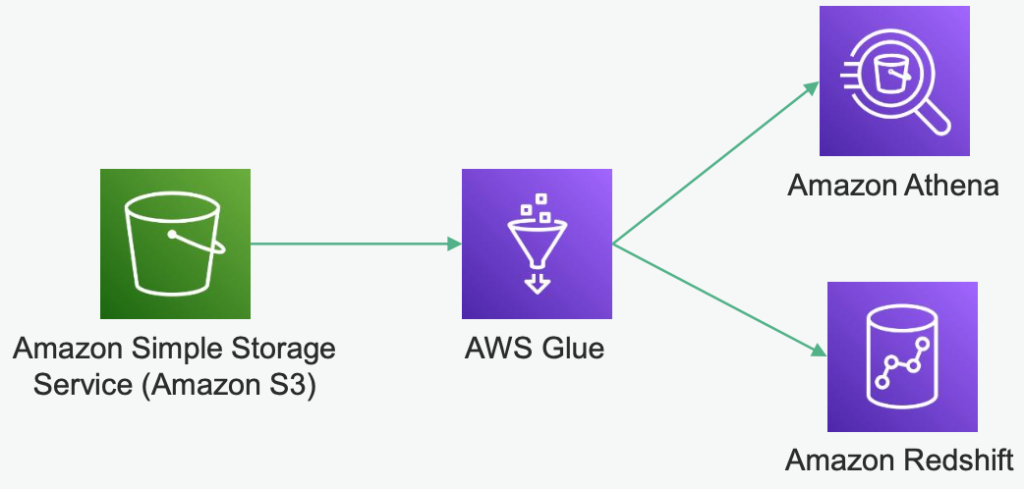
Build a Data Lake Architecture on AWS
Comparison
| Feature | S3 → Glue → Athena | S3 → Glue → Redshift |
|---|---|---|
| Cost | Lower (pay-as-you-go, serverless) | Higher (compute and storage costs for Redshift) |
| Performance | Adequate for ad-hoc queries, depends on S3 data | High performance for structured, large-scale data |
| Complexity | Simple setup, minimal infrastructure management | More complex, requires Redshift cluster tuning |
| Use Case | Ad-hoc querying, raw data analysis | Persistent data warehouse, BI dashboard support |
| Data Type Support | Structured, semi-structured, and unstructured | Primarily structured data |
| Scalability | Automatically scales with S3 | Manual scaling for Redshift clusters |
1. AWS S3 → AWS Glue → AWS Athena
Workflow
- AWS S3: Stores raw or semi-structured data in various formats (JSON, CSV, Parquet, etc.).
- AWS Glue: Crawls the S3 data, creates metadata in a catalog, and transforms data if needed.
- AWS Athena: A serverless query service that directly queries data stored in S3 using SQL.
Features
- Cost-Effective:
- You pay only for the queries run on Athena and the storage in S3.
- Schema-on-Read:
- Data isn’t transformed or loaded into another database; the schema is applied at query time.
- Serverless:
- Athena doesn’t require infrastructure setup; it scales automatically.
- Query Performance:
- Best for ad-hoc analysis; query performance depends on data format and partitioning.
Use Cases
- Ad-hoc querying of raw or semi-structured data.
- Exploratory data analysis.
- Cost-efficient analytics for intermittent workloads.
- Ideal for teams that don’t need a persistent, optimized data warehouse.
Advantages
- No need for a data warehouse.
- Supports structured, semi-structured, and unstructured data directly from S3.
- Lower operational overhead.
Limitations
- Query performance might degrade with large, unoptimized datasets.
- Not suitable for complex OLAP (Online Analytical Processing) workloads requiring significant aggregations or joins.
2. AWS S3 → AWS Glue → AWS Redshift
Workflow
- AWS S3: Stores raw or semi-structured data in various formats.
- AWS Glue: Transforms and loads data into an AWS Redshift data warehouse.
- AWS Redshift: A fully managed, scalable data warehouse optimized for OLAP workloads.
Features
- Schema-on-Write:
- Data is transformed and loaded into Redshift tables during ETL (Extract, Transform, Load) using Glue.
- Optimized for OLAP:
- Redshift is built for high-performance querying, especially for complex aggregations and joins.
- Scalability:
- Supports large-scale data processing with optimized storage and query engines.
- Integration:
- Integrates well with BI tools like Tableau, QuickSight, and Looker for reporting and visualization.
Use Cases
- Persistent data warehouse for structured and transformed data.
- BI dashboards and operational analytics requiring high-performance querying.
- Workloads involving frequent complex queries on large datasets.
Advantages
- High performance for large-scale, complex queries.
- Advanced analytics and integration with BI tools.
- Optimized storage and indexing.
Limitations
- Higher cost due to Redshift cluster management and compute resources.
- More complex to manage compared to serverless Athena.
How to Choose?
- Choose S3 → Glue → Athena if:
- You need cost-effective, ad-hoc querying on raw data.
- You want a lightweight, serverless architecture.
- Your use cases don’t involve frequent complex queries or BI tools.
- Choose S3 → Glue → Redshift if:
- You need a persistent, optimized data warehouse for structured data.
- You have frequent, complex query requirements or BI dashboards.
- You need fast performance on structured, transformed datasets.
Potential Hybrid Approach
- Use S3 → Glue → Athena for initial data exploration and processing.
- Load cleaned and transformed data into Redshift for reporting and BI analysis. This gives you the flexibility of both worlds.
Resiliency
- When you’re thinking about resiliency, it’s all about distributing your servers across different racks, data centers, regions, so that you have backups of all of your data and all of your systems across those different zones.
- And making sure you understand that you’re over-provisioning to handle the failure of any one of those entities.
When designing a large-scale system, resiliency is crucial. It involves planning for and mitigating potential failures at various levels, from individual servers to entire regions.
Key Considerations for Resiliency:
- Data Replication:
- Replicate data across multiple servers or data centers to ensure data availability in case of failures.
- Use technologies like MongoDB’s replication to maintain data consistency.
- Geographic Distribution:
- Distribute servers across different regions to minimize the impact of regional outages.
- Use geo-routing techniques to direct traffic to the nearest available region.
- Capacity Planning:
- Overprovision resources to handle increased load during failures.
- Ensure that remaining regions have sufficient capacity to accommodate traffic from failed regions.
- Failure Detection and Recovery:
- Implement robust monitoring systems to detect failures promptly.
- Have automated recovery mechanisms in place to restore services quickly.
Trade-offs and Considerations:
- Cost: Implementing high levels of resiliency can be expensive due to increased hardware and operational costs.
- Complexity: Distributed systems are inherently more complex to manage and maintain.
- Performance: Geographic distribution can introduce latency and network issues.
Ultimately, the level of resiliency required depends on the specific needs of the system. For mission-critical systems, it’s essential to prioritize resiliency and invest in the necessary infrastructure and processes.
Please visit https: https://codeandalgo.com for more such contents.